 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNative Audio-Visual Alignment for Generation
May 28, 2026Joint audio-video generation aims to synthesize temporally synchronized and semantically coherent visual-acoustic content. However, existing open-source methods mainly rely on either dual-tower designs with posterior alignment or fully unified tri-modal designs that mix textual context, audio and video in one shared space. The former weakens fine-grained audio-video co-evolution, while the latter couples semantic conditioning with low-level synchronization. To address these limitations, we propose NAVA, a Native Audio-Visual Alignment framework for joint audio-video generation. NAVA is built upon context-conditioned native audio-visual alignment: it first establishes audio-video correspondence in a dedicated interaction space, and then uses external context to condition the joint denoising process. Specifically, NAVA is instantiated with an Align-then-Fuse MMDiT architecture, which transitions from modality-aware audio-video alignment to modality-shared joint denoising. Furthermore, we introduce Timbre-in-Context Conditioning to associate reference timbre cues with corresponding speech spans to achieve controllable speech timbre. Experiments on Verse-Bench and Seed-TTS, together with a user study, demonstrate that NAVA achieves superior video quality, precise audio-visual synchronization, competitive audio quality, and stronger reference-timbre controllability using only 6.3B parameters.
HRM-Text: Efficient Pretraining Beyond Scaling
May 20, 2026The current pretraining paradigm for large language models relies on massive compute and internet-scale raw text, creating a significant barrier to foundational research. In contrast, biological systems demonstrate highly sample-efficient learning through multi-timescale processing, such as the functional organization of the frontoparietal loop. Taking this as inspiration, we introduce HRM-Text, which replaces standard Transformers with a Hierarchical Recurrent Model (HRM) that decouples computation into slow-evolving strategic and fast-evolving execution layers. To stabilize this deep recurrence for language modeling, we introduce MagicNorm and warmup deep credit assignment. Furthermore, instead of standard raw-text pretraining, we train exclusively on instruction-response pairs using a task-completion objective and PrefixLM masking. Serving as an empirical existence proof of efficient pretraining, a 1B-parameter HRM-Text model trained from scratch on only 40 billion unique tokens and $1,500 budget achieves 60.7% on MMLU, 81.9% on ARC-C, 82.2% on DROP, 84.5% on GSM8K, and 56.2% on MATH. Despite utilizing roughly 100-900x fewer training tokens and 96-432x less estimated compute than standard baselines, HRM-Text performs competitively with 2-7B parameter open models. These results demonstrate that co-designing architectures and objectives can radically reduce the compute-to-performance ratio, making pretraining from scratch accessible to the broader research community.
Sample Complexity of Transfer Learning: An Optimal Transport Approach
May 19, 2026Transfer learning is an essential technique for many machine learning/AI models of complex structures such as large language models and generative AI. The essence of transfer learning is to leverage knowledge from resolved source tasks for a new target task, especially when the sample size $m$ of the training data for the latter is low. In this work, we rigorously analyze the potential benefit of transfer learning in terms of sample efficiency. Specifically, taking an optimal transport viewpoint of transfer learning, we find that when the data dimension $d$ is higher than $3$, the sample complexity for transfer learning is $O(m^{-(α+1)/d})$, with $α$ indicating the smoothness of the data distribution, as opposed to the $O(m^{-p/d})$ sample complexity for direct learning with $p$ indicating the smoothness of the optimal target model. Our finding theoretically supports a better sample efficiency for transfer learning, when the target task is optimizing over a family of not-so-smooth models (i.e., highly complex networks with the possible use of non-smooth activation functions). Using image classification as an example, we numerically demonstrate the sample efficiency for transfer learning, that is, in the data hungry regime, the model performance can be significantly improved by transfer learning.
GAIN: Multiplicative Modulation for Domain Adaptation
Apr 06, 2026Adapting LLMs to new domains causes forgetting because standard methods (full fine-tuning, LoRA) inject new directions into the weight space. We propose GAIN, which re-emphasizes existing features through multiplicative modulation W_new = S * W. The learned diagonal matrix S is applied to the attention output projection and optionally the FFN. The principle mirrors gain modulation in neuroscience, where neurons adapt to context by scaling response strength while preserving selectivity. We evaluate GAIN on five models from four families (774M to 70B), adapting sequentially across eight domains. GAIN-FFN matches LoRA's in-domain adaptation, but their effects on previously trained domains are opposite: GAIN-FFN improves them by 7-13% (validation PPL), while LoRA degrades them by 18-36%. Downstream accuracy confirms the pattern: for example, after seven sequential adaptations on Qwen2.5, GAIN-FFN degrades BoolQ by only 0.8% while LoRA damages it by 14.9%. GAIN adds 46K-230K parameters per model and can be absorbed into the pretrained weights for zero inference cost.
Efficient and Scalable Granular-ball Graph Coarsening Method for Large-scale Graph Node Classification
Mar 31, 2026Graph Convolutional Network (GCN) is a model that can effectively handle graph data tasks and has been successfully applied. However, for large-scale graph datasets, GCN still faces the challenge of high computational overhead, especially when the number of convolutional layers in the graph is large. Currently, there are many advanced methods that use various sampling techniques or graph coarsening techniques to alleviate the inconvenience caused during training. However, among these methods, some ignore the multi-granularity information in the graph structure, and the time complexity of some coarsening methods is still relatively high. In response to these issues, based on our previous work, in this paper, we propose a new framework called Efficient and Scalable Granular-ball Graph Coarsening Method for Large-scale Graph Node Classification. Specifically, this method first uses a multi-granularity granular-ball graph coarsening algorithm to coarsen the original graph to obtain many subgraphs. The time complexity of this stage is linear and much lower than that of the exiting graph coarsening methods. Then, subgraphs composed of these granular-balls are randomly sampled to form minibatches for training GCN. Our algorithm can adaptively and significantly reduce the scale of the original graph, thereby enhancing the training efficiency and scalability of GCN. Ultimately, the experimental results of node classification on multiple datasets demonstrate that the method proposed in this paper exhibits superior performance. The code is available at https://anonymous.4open.science/r/1-141D/.
An Evolutionary Algorithm with Probabilistic Annealing for Large-scale Sparse Multi-objective Optimization
Mar 12, 2026Large-scale sparse multi-objective optimization problems (LSMOPs) are prevalent in real-world applications, where optimal solutions typically contain only a few nonzero variables, such as in adversarial attacks, critical node detection, and sparse signal reconstruction. Since the function evaluation of LSMOPs often relies on large-scale datasets involving a large number of decision variables, the search space becomes extremely high-dimensional. The coexistence of sparsity and high dimensionality greatly intensifies the conflict between exploration and exploitation, making it difficult for existing multi-objective evolutionary algorithms (MOEAs) to identify the critical nonzero decision variables within limited function evaluations. To address this challenge, this paper proposes an evolutionary algorithm with probabilistic annealing for large-scale sparse multi-objective optimization. The algorithm is driven by two probability vectors with distinct entropy characteristics: a convergence-oriented probability vector with relatively low entropy ensures stable exploitation, whereas an annealed probability vector with gradually decreasing entropy enables an adaptive transition from global exploration to local refinement. By integrating these complementary search dynamics, the proposed algorithm achieves a dynamic equilibrium between exploration and exploitation. Experimental results on benchmark problems and real-world applications demonstrate that the proposed algorithm outperforms state-of-the-art evolutionary algorithms in terms of both convergence and diversity.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
RAL2M: Retrieval Augmented Learning-To-Match Against Hallucination in Compliance-Guaranteed Service Systems
Jan 06, 2026Hallucination is a major concern in LLM-driven service systems, necessitating explicit knowledge grounding for compliance-guaranteed responses. In this paper, we introduce Retrieval-Augmented Learning-to-Match (RAL2M), a novel framework that eliminates generation hallucination by repositioning LLMs as query-response matching judges within a retrieval-based system, providing a robust alternative to purely generative approaches. To further mitigate judgment hallucination, we propose a query-adaptive latent ensemble strategy that explicitly models heterogeneous model competence and interdependencies among LLMs, deriving a calibrated consensus decision. Extensive experiments on large-scale benchmarks demonstrate that the proposed method effectively leverages the "wisdom of the crowd" and significantly outperforms strong baselines. Finally, we discuss best practices and promising directions for further exploiting latent representations in future work.
TRKT: Weakly Supervised Dynamic Scene Graph Generation with Temporal-enhanced Relation-aware Knowledge Transferring
Aug 07, 2025Dynamic Scene Graph Generation (DSGG) aims to create a scene graph for each video frame by detecting objects and predicting their relationships. Weakly Supervised DSGG (WS-DSGG) reduces annotation workload by using an unlocalized scene graph from a single frame per video for training. Existing WS-DSGG methods depend on an off-the-shelf external object detector to generate pseudo labels for subsequent DSGG training. However, detectors trained on static, object-centric images struggle in dynamic, relation-aware scenarios required for DSGG, leading to inaccurate localization and low-confidence proposals. To address the challenges posed by external object detectors in WS-DSGG, we propose a Temporal-enhanced Relation-aware Knowledge Transferring (TRKT) method, which leverages knowledge to enhance detection in relation-aware dynamic scenarios. TRKT is built on two key components:(1)Relation-aware knowledge mining: we first employ object and relation class decoders that generate category-specific attention maps to highlight both object regions and interactive areas. Then we propose an Inter-frame Attention Augmentation strategy that exploits optical flow for neighboring frames to enhance the attention maps, making them motion-aware and robust to motion blur. This step yields relation- and motion-aware knowledge mining for WS-DSGG. (2) we introduce a Dual-stream Fusion Module that integrates category-specific attention maps into external detections to refine object localization and boost confidence scores for object proposals. Extensive experiments demonstrate that TRKT achieves state-of-the-art performance on Action Genome dataset. Our code is avaliable at https://github.com/XZPKU/TRKT.git.
GBGC: Efficient and Adaptive Graph Coarsening via Granular-ball Computing
Jun 24, 2025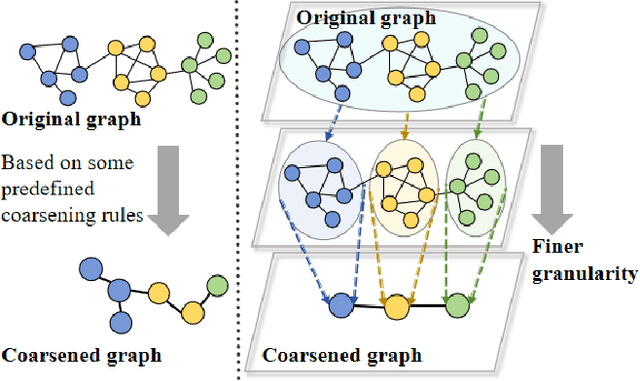
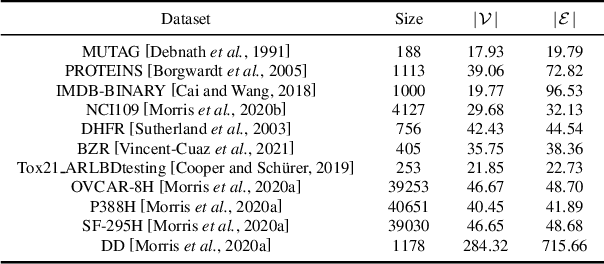
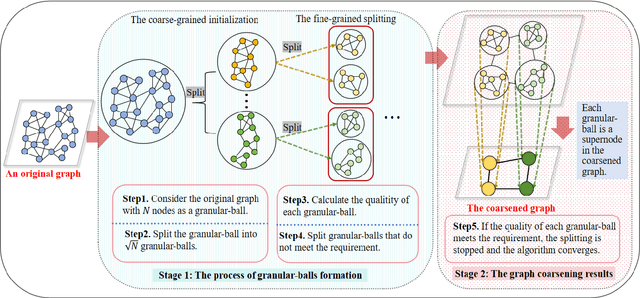

The objective of graph coarsening is to generate smaller, more manageable graphs while preserving key information of the original graph. Previous work were mainly based on the perspective of spectrum-preserving, using some predefined coarsening rules to make the eigenvalues of the Laplacian matrix of the original graph and the coarsened graph match as much as possible. However, they largely overlooked the fact that the original graph is composed of subregions at different levels of granularity, where highly connected and similar nodes should be more inclined to be aggregated together as nodes in the coarsened graph. By combining the multi-granularity characteristics of the graph structure, we can generate coarsened graph at the optimal granularity. To this end, inspired by the application of granular-ball computing in multi-granularity, we propose a new multi-granularity, efficient, and adaptive coarsening method via granular-ball (GBGC), which significantly improves the coarsening results and efficiency. Specifically, GBGC introduces an adaptive granular-ball graph refinement mechanism, which adaptively splits the original graph from coarse to fine into granular-balls of different sizes and optimal granularity, and constructs the coarsened graph using these granular-balls as supernodes. In addition, compared with other state-of-the-art graph coarsening methods, the processing speed of this method can be increased by tens to hundreds of times and has lower time complexity. The accuracy of GBGC is almost always higher than that of the original graph due to the good robustness and generalization of the granular-ball computing, so it has the potential to become a standard graph data preprocessing method.